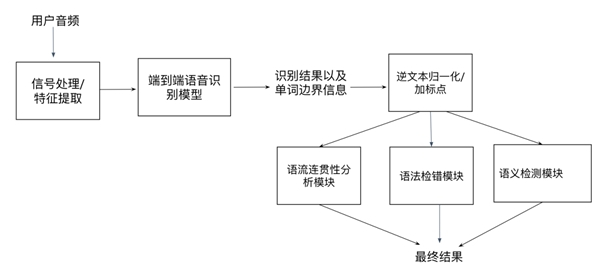
隨著人工智能技術從實驗室走向千行百業,作為其算力基石的人工智能芯片,已成為全球科技競爭的戰略制高點。從訓練巨量參數的“大模型”到執行具體任務的終端設備,不同場景對芯片的架構、能效和成本提出了迥異的要求。當前,產業格局呈現多元化競爭態勢,既有英偉達憑借其CUDA生態在GPU領域構筑的深厚壁壘,也有谷歌TPU、華為昇騰等專用AI芯片的崛起,還有 Cerebras、Graphcore 等創業公司探索的顛覆性架構。
在追求“最強大腦”的征程中,衡量標準已不單純是峰值算力。能效比、內存帶寬、軟件棧的易用性與豐富度、以及對特定算法(如Transformer)的優化程度,共同構成了核心競爭力。尤其是在人工智能通用應用系統的構建中,芯片需要具備高度的靈活性和可擴展性,以應對從云端訓練到邊緣推理,從視覺識別到自然語言處理等紛繁復雜的任務。
誰能成就支撐人工智能通用應用系統的“最強大腦”?答案可能并非唯一。一種觀點認為,通過先進封裝技術將不同功能的芯粒(Chiplet)集成,形成異構計算系統,是兼顧性能與靈活性的可行路徑。另一種趨勢是“軟硬協同”的深度優化,即針對主流AI框架和算法,從芯片指令集層面進行定制設計。開源指令集RISC-V的興起,也為AI芯片創新提供了新的底層架構選擇,可能催生更多差異化的解決方案。
可以預見,人工智能芯片的競爭將是生態體系的全面較量。它不僅關乎硬件本身的性能,更依賴于整個軟件工具鏈、開發者社區、應用場景的深度融合。那個能夠以最高效率、最低成本賦能千行百業智能化轉型的“最強大腦”,或許將誕生于最開放、最包容、最貼近實際需求的產業生態之中。這場關于算力王座的角逐,才剛剛進入精彩的中盤。